本文由 简悦 SimpRead 转码, 原文地址 juejin.cn
之前的两篇文章对 GCD 队列和调度函数进行了解析。本文将继续讲解 GCD 里面一些使用率较低的函数的使用。
栅栏函数
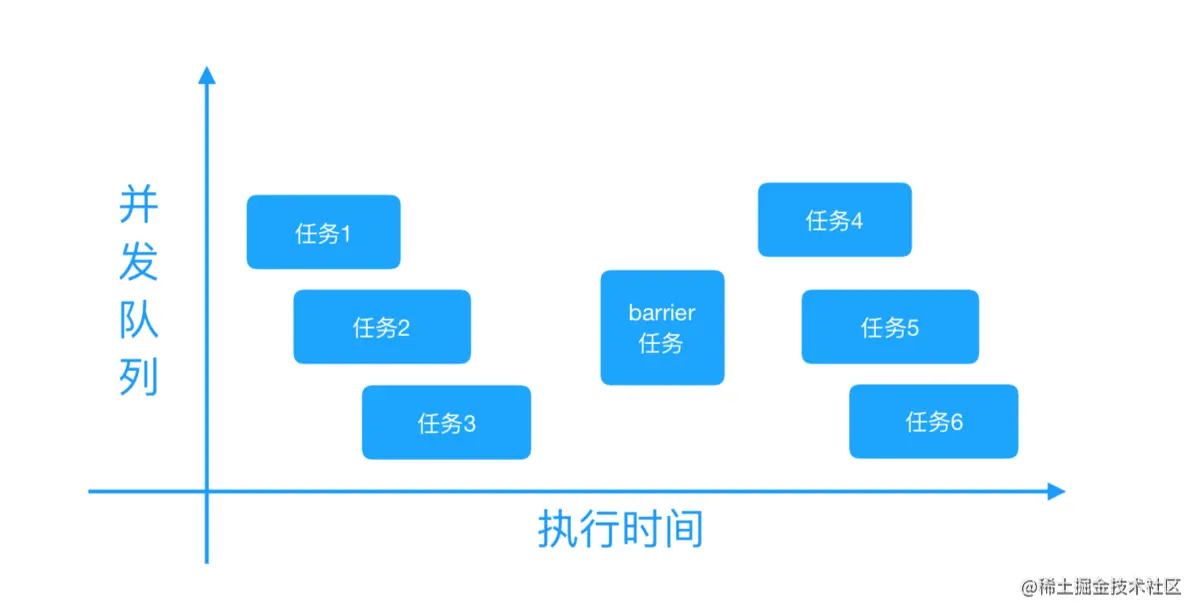
我们在开发中经常会使用到并发队列+异步函数,来开启新线程去完成耗时任务,但这样的操作存在一个漏洞,耗时任务的执行会呈现无序性,从而淡化队列的概念,而在特定的情况下,个别任务执行的条件是前置任务完成。这种情况使用并发队列 + 异步函数是无法实现的,这时候就需要栅栏函数出马了。
使用dispatch_barrier_async添加的任务,会将队列里面的任务分成 3 部分,dispatch_barrier_async添加之前的所有任务,会异步执行,一直到最后一个任务完成再执行dispatch_barrier_async添加的任务,该任务执行完成后,再异步执行 dispatch_barrier_async添加之后的所有任务。dispatch_barrier_async添加的任务像一个栅栏一样把队列里面的任务划分开。
- (void)barrier {
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.osDemo.concurrent", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(concurrentQueue, ^{
usleep(20);
NSLog(@"任务1---%@",[NSThread currentThread]);
});
dispatch_async(concurrentQueue, ^{
usleep(30);
NSLog(@"任务3---%@",[NSThread currentThread]);
});
dispatch_async(concurrentQueue, ^{
usleep(40);
NSLog(@"任务3---%@",[NSThread currentThread]);
});
dispatch_barrier_async(concurrentQueue, ^{
usleep(40);
NSLog(@"任务4---%@",[NSThread currentThread]);
});
dispatch_async(concurrentQueue, ^{
usleep(40);
NSLog(@"任务5---%@",[NSThread currentThread]);
});
dispatch_async(concurrentQueue, ^{
usleep(40);
NSLog(@"任务6---%@",[NSThread currentThread]);
});
}执行结果永远是任务 4⃣️再任务 1⃣️2⃣️3⃣️之后,任务 5⃣️6⃣️再任务 4⃣️之后。
barrier的函数。我们也可以思考一下,栅栏函数的目的是让队列里的任务乱中有序,而串行队列的dq_witdh = 1, 人家本来就排着队,秩序非常好,还需要栅栏函数么?
思考:栅栏函数为什么栏不住全局并发队列
在栅栏函数的使用过程中,我们发现栅栏函数无法栏住全局并发队列。个人任务,在全局并发队列中不仅有开发者的任务,还有系统的任务,如果我们用我们的任务去栏住系统的任务,可能会导致一些未知的错误。栅栏函数对全局并发队列无效,所以我们在开发的时候一定要注意。
栅栏函数实现多读单写
栅栏函数实现多读单写,这是栅栏函数最典型的应用,我在面试的时候确实也碰到了让手写代码的。
需求分析: 读写异步,读写互斥,写写互斥,读读可并行。
//栅栏函数实现多读单写
- (void)initReadWrite {
self.readWriteQueue = dispatch_queue_create("com.demo.readWrite", DISPATCH_QUEUE_CONCURRENT);
}
- (void)write:(NSString *)str {
dispatch_barrier_async(self.readWriteQueue, ^{
usleep(40);
NSLog(@"我是一个写任务");
});
}
- (void)readWithId:(NSString *)taskId completion:(void (^)(NSString *str, NSError *error))completion{
dispatch_async(self.readWriteQueue, ^{
usleep(40);
NSLog(@"我是一个读任务");
completion(@"result",nil);
});
}注意:这里如果有多个读任务,再有一个写任务进来的时候,写任务会等读任务都完成了,再进行写操作,反之,如果队列里面有多个写任务,他们会一一执行完成,再读任务进入后会等写任务执行完,并发执行读任务。
调度组
再开发过程中,经常遇到一个页面里面有多个请求,而这多个请求之间还有关联关系。以一个视频播放页面为例,上一级页面传入参数为节目 ID,需要从 A 接口获取视频播放的地址,从 B 接口获取节目的信息,从 C 接口获取大数据推荐节目表。需要等这 3 个接口的数据都回来才能展示 UI。 这时候就需要我们的调度组来接受所有任务完成的回调了。
- (void)groupTest01 {
dispatch_group_t group = dispatch_group_create();
dispatch_group_enter(group);
[self asyncInvoke:^{
NSLog(@"网络请求A回来了");
dispatch_group_leave(group);
}];
dispatch_group_enter(group);
[self asyncInvoke:^{
NSLog(@"网络请求B回来了");
dispatch_group_leave(group);
}];
dispatch_group_enter(group);
[self asyncInvoke:^{
NSLog(@"网络请求C回来了");
dispatch_group_leave(group);
}];
dispatch_group_notify(group, dispatch_get_main_queue(), ^{
NSLog(@"绘制ui");
});
}
//模仿异步执行
- (void)asyncInvoke:(dispatch_block_t)block {
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_async(queue, block);
}这种情况是AFN(示例中使用asyncInvoke模拟)已经去管理了线程的调度,如果需要自己去操作队列,调度组还有一种使用的方式:
//任务1,任务2在子线程并发执行,任务3等任务1和任务2完成后再在子线程执行
- (void)groupTest02 {
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
dispatch_group_async(group, queue, ^{
for (int i = 0 ; i < 10; i++) {
NSLog(@"%s-任务 1 - %@",__func__, [NSThread currentThread]);
}
});
dispatch_group_async(group, queue, ^{
for (int i = 0 ; i < 15; i++) {
NSLog(@"%s-任务 2 - %@",__func__, [NSThread currentThread]);
}
});
dispatch_group_notify(group, queue, ^{
NSLog(@" %@", [NSThread currentThread]);
dispatch_async(dispatch_get_main_queue(), ^{
for (int i = 0 ; i < 5; i++) {
NSLog(@"%s-任务 3 - %@",__func__, [NSThread currentThread]);
}
});
});
}信号量
dispatch_semaphore_t的常用方法有
dispatch_semaphore_create创建信号量dispatch_semaphore_wait等待信号量dispatch_semaphore_signal释放信号量
使用dispatch_semaphore_create 和一个初始值来创建一个信号量,当dispatch_semaphore_wait的时候,如果这个初始值大于 0,初始值减 1,代码继续往下执行,如果值等于 0 则代码等待(忙等),知道值大于 0 的时候再减 1 继续执行,当dispatch_semaphore_signal的时候,信号量的值加 1。
信号量的使用
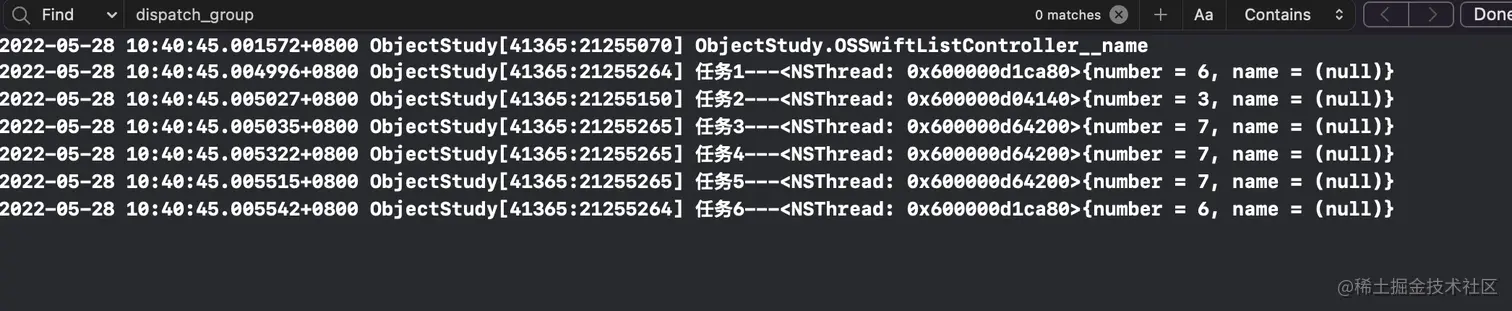
下面代码没有使用信号量的时候,值会非常大。
- (void)noSemaphore {
__block int a = 0;
while (a < 5) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"里面的a的值:%d-----%@", a, [NSThread currentThread]);
a++;
});
}
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, 2), dispatch_get_global_queue(0, 0), ^{
NSLog(@"外面的a的值:%d", a);
});
}使用信号量控制:
- (void)semaphore {
dispatch_semaphore_t semaphore = dispatch_semaphore_create(0);
__block int a = 0;
while (a < 5) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"里面的a的值:%d-----%@", a, [NSThread currentThread]);
dispatch_semaphore_signal(semaphore);
a++;
});
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
}
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, 2), dispatch_get_global_queue(0, 0), ^{
NSLog(@"外面的a的值:%d", a);
});
}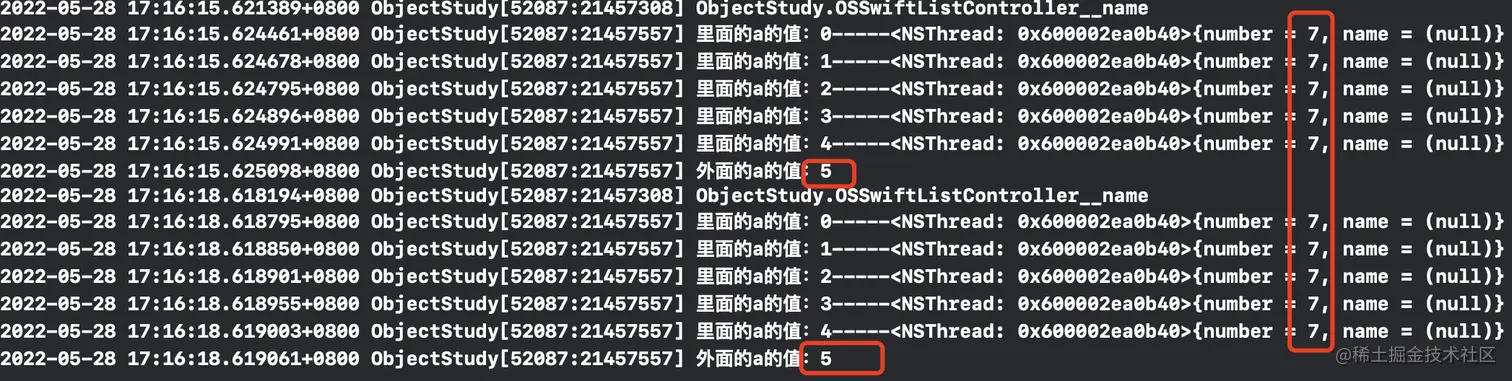
这就体现了信号量的一个作用 -- 控制并发队列的数量。例如:
//信号量控制并发队列线程数量
- (void)semaphoreControlThreadCount {
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.osDemo.semaphore.queue", DISPATCH_QUEUE_CONCURRENT);
dispatch_semaphore_t semaphore = dispatch_semaphore_create(2);
for (int i = 0; i < 10; i++) {
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
dispatch_async(concurrentQueue, ^{
usleep(arc4random_uniform(1000));
NSLog(@"做完了一个耗时任务%@",[NSThread currentThread]);
dispatch_semaphore_signal(semaphore);
});
}
}执行结果:
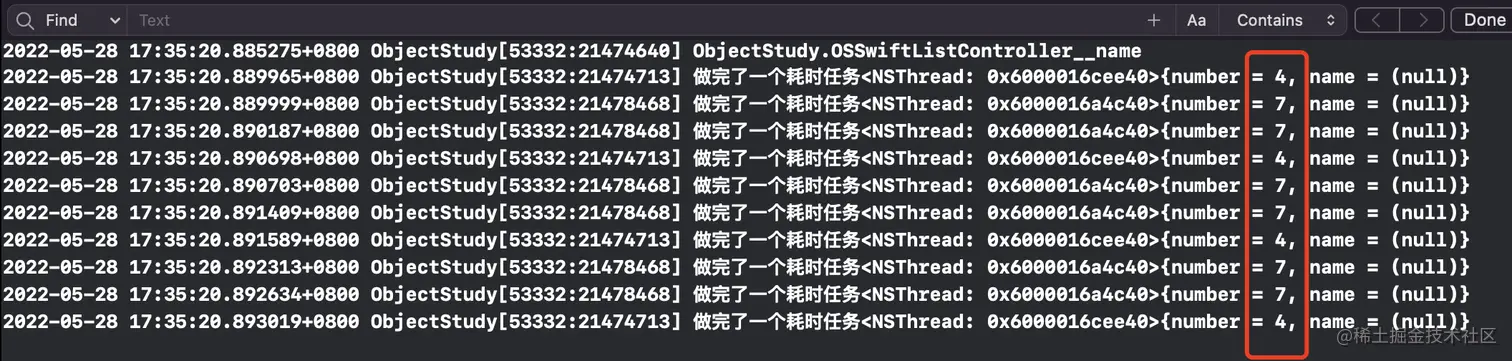
⚠️:使用信号量的时候一定要注意signal和wait要一一对应,不然有可能导致崩溃。
源码解读
我们来看看 dispatch_semaphore 的这三个方法的源码实现。
dispatch_semaphore_create
dispatch_semaphore_t
dispatch_semaphore_create(intptr_t value)
{
dispatch_semaphore_t dsema;
// If the internal value is negative, then the absolute of the value is
// equal to the number of waiting threads. Therefore it is bogus to
// initialize the semaphore with a negative value.
//初始值必须大于等于0
if (value < 0) {
return DISPATCH_BAD_INPUT;
}
//开辟内存
dsema = _dispatch_object_alloc(DISPATCH_VTABLE(semaphore),
sizeof(struct dispatch_semaphore_s));
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
dsema->do_targetq = _dispatch_get_default_queue(false);
//保存初始值
dsema->dsema_value = value;
//初始化方法
_dispatch_sema4_init(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
dsema->dsem_orig = value;
return dsema;
}- 首先如果信号为
小于0,则返回一个DISPATCH_BAD_INPUT类型对象,也就是返回个_Nonnull - 如果信号
大于等于0,就会dispatch_semaphore_t对象dsema进行初始化,并返回dsema对象
dispatch_semaphore_wait
intptr_t
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
long value = os_atomic_dec2o(dsema, dsema_value, acquire);
if (likely(value >= 0)) {
return 0;
}
return _dispatch_semaphore_wait_slow(dsema, timeout);
}- 对信号量的值
-1,如果值大于等于0(原来的值大于 0),啥也不干。 - 如
果-1以后的值小于0,执行_dispatch_semaphore_wait_slow。
DISPATCH_NOINLINE
static intptr_t
_dispatch_semaphore_wait_slow(dispatch_semaphore_t dsema,
dispatch_time_t timeout)
{
long orig;
_dispatch_sema4_create(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
switch (timeout) {
default:
if (!_dispatch_sema4_timedwait(&dsema->dsema_sema, timeout)) {
break;
}
// Fall through and try to undo what the fast path did to
// dsema->dsema_value
case DISPATCH_TIME_NOW:
orig = dsema->dsema_value;
while (orig < 0) {
if (os_atomic_cmpxchgv2o(dsema, dsema_value, orig, orig + 1,
&orig, relaxed)) {
return _DSEMA4_TIMEOUT();
}
}
// Another thread called semaphore_signal().
// Fall through and drain the wakeup.
case DISPATCH_TIME_FOREVER:
_dispatch_sema4_wait(&dsema->dsema_sema);
break;
}
return 0;
}- 这里对传入的
timeout进行了判断,我们一般都是使用的DISPATCH_TIME_FOREVER - 执行
_dispatch_sema4_wait
_dispatch_sema4_wait(_dispatch_sema4_t *sema)
{
kern_return_t kr;
do {
kr = semaphore_wait(*sema);
} while (kr == KERN_ABORTED);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
}- 这里进行了
do-while循环,这个♻️就相当于忙等。
所以回到最初,如果wait的时候,信号量的值-1之后小于0,将会等待。
dispatch_semaphore_signal
DISPATCH_NOINLINE
intptr_t
_dispatch_semaphore_signal_slow(dispatch_semaphore_t dsema)
{
_dispatch_sema4_create(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
_dispatch_sema4_signal(&dsema->dsema_sema, 1);
return 1;
}
intptr_t
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
long value = os_atomic_inc2o(dsema, dsema_value, release);
if (likely(value > 0)) {
return 0;
}
if (unlikely(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_semaphore_signal()");
}
return _dispatch_semaphore_signal_slow(dsema);
}- 首先信号量的值
+1 - 如果加完,值
大于0,直接返回。 - 否则执行
_dispatch_semaphore_signal_slow
一次性代码
我看有很多文章中把这个dispatch_once叫做单例。其实个人认为是个错误的称呼,正确应该叫一次性代码,单例只是其中的一个应用。
一次性代码的使用
在平时的开发中,一次性代码的使用主要有两方面,单例的初始化和方法交换保证只交换一次,例如
+ (ClassType *)sharedManager {
static ClassType *sharedManager = nil;
static dispatch_once_t oneToken;
dispatch_once(&oneToken,^{
sharedManager = [[ClassType alloc] init];
});
return sharedManager;
}+ (void)load {
static dispatch_once_t dispatchOnce;
dispatch_once(&dispatchOnce, ^{
Class cls = [self class];
SEL originalSel = @selector(viewDidLoad);
SEL swizzledSel = @selector(viewDidLoadSwizzled);
Method originalMethod = class_getClassMethod(cls, originalSel);
Method swizzledMethod = class_getClassMethod(cls, swizzledSel);
method_exchangeImplementations(originalMethod, swizzledMethod);
});
}可以看到通过一次性代码,我们可以确保代码在运行的过程中只运行一次。那么底层是如何实现的呢?这就需要我们在 libdispatch 源码中去寻找答案。
一次性代码源码浅析
直接来到一次性代码的实现
DISPATCH_NOINLINE
void
dispatch_once_f(dispatch_once_t *val, void *ctxt, dispatch_function_t func)
{
dispatch_once_gate_t l = (dispatch_once_gate_t)val;
#if !DISPATCH_ONCE_INLINE_FASTPATH || DISPATCH_ONCE_USE_QUIESCENT_COUNTER
uintptr_t v = os_atomic_load(&l->dgo_once, acquire);
if (likely(v == DLOCK_ONCE_DONE)) {
return;
}
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
//已经完成分支
if (likely(DISPATCH_ONCE_IS_GEN(v))) {
return _dispatch_once_mark_done_if_quiesced(l, v);
}
#endif
#endif
//未执行过分支
if (_dispatch_once_gate_tryenter(l)) {
return _dispatch_once_callout(l, ctxt, func);
}
//正在别的线程执行分支
return _dispatch_once_wait(l);
}我们可以将代码分为 3 个分支,逐步来解析。 这里有个宏定义DISPATCH_ONCE_USE_QUIESCENT_COUNTER:
#if defined(__x86_64__) || defined(__i386__) || defined(__s390x__)
#define DISPATCH_ONCE_USE_QUIESCENT_COUNTER 0
#elif __APPLE__
#define DISPATCH_ONCE_USE_QUIESCENT_COUNTER 1
#else
#define DISPATCH_ONCE_USE_QUIESCENT_COUNTER 0
#endif可以看到如果是苹果系统,直接是1,所以我们需要看 #if DISPATCH_ONCE_USE_QUIESCENT_COUNTER下面的逻辑。条件版判里面的宏定义如下:
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
//设置已经完成
#define DISPATCH_ONCE_MAKE_GEN(gen) (((gen) << 2) + DLOCK_FAILED_TRYLOCK_BIT)
//判断是否完成
#define DISPATCH_ONCE_IS_GEN(gen) (((gen) & 3) == DLOCK_FAILED_TRYLOCK_BIT)这里就体现出了,位运算的巧妙了。看设置已经完成的宏,是在callout流程里面调用的左移2位,然后 + 0x10(DLOCK_FAILED_TRYLOCK_BIT),如果执行过次操作,下面的判断一定是YES,下面的判断是与0x11,即获取低 2 位值,看是否等于0x10。
在看未执行分支,便可以找到使用已经完成宏的调用:
DISPATCH_NOINLINE
static void
_dispatch_once_callout(dispatch_once_gate_t l, void *ctxt,
dispatch_function_t func)
{
//执行block
_dispatch_client_callout(ctxt, func);
//设置执行状态
_dispatch_once_gate_broadcast(l);
}_dispatch_client_callout 实现
#undef _dispatch_client_callout
DISPATCH_NOINLINE
void
_dispatch_client_callout(void *ctxt, dispatch_function_t f)
{
_dispatch_get_tsd_base();
void *u = _dispatch_get_unwind_tsd();
if (likely(!u)) return f(ctxt);
_dispatch_set_unwind_tsd(NULL);
f(ctxt);
_dispatch_free_unwind_tsd();
_dispatch_set_unwind_tsd(u);
}_dispatch_once_gate_broadcast 实现
DISPATCH_ALWAYS_INLINE
static inline void
_dispatch_once_gate_broadcast(dispatch_once_gate_t l)
{
dispatch_lock value_self = _dispatch_lock_value_for_self();
uintptr_t v;
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
//获取已经完成的值
v = _dispatch_once_mark_quiescing(l);
#else
v = _dispatch_once_mark_done(l);
#endif
if (likely((dispatch_lock)v == value_self)) return;
_dispatch_gate_broadcast_slow(&l->dgo_gate, (dispatch_lock)v);
}DISPATCH_ALWAYS_INLINE
static inline uintptr_t
_dispatch_once_mark_quiescing(dispatch_once_gate_t dgo)
{
//线程安全
return os_atomic_xchg(&dgo->dgo_once, _dispatch_once_generation(), release);
}DISPATCH_ALWAYS_INLINE
static inline uintptr_t
_dispatch_once_generation(void)
{
uintptr_t value;
value = *(volatile uintptr_t *)_COMM_PAGE_CPU_QUIESCENT_COUNTER;
//这个宏 与运算👍
return (uintptr_t)DISPATCH_ONCE_MAKE_GEN(value);
}DISPATCH_ONCE_MAKE_GEN这个便是👆的设置已经完成的值。
一次性代码的原理:
- 使用
dispatch_once_t来标记block执行的状态。 - 如果是未被执行状态,直接执行。
- 如果是已经执行过,直接返回。
- 如果正在被其他线程执行,等待。
最后
其实 GCD 中还有很多实用且方便的函数,例如dispatch_after、dispatch_timer、disptch_apply、disptch_source等。由于时间和篇幅有限,这里就不一一列举,笔者也想在此抛个砖,希望有大佬愿意分享其他函数的底层原理。如有链接可以放评论区。当然,之后弄完整个八股文系列,希望还有余力能把剩下的几个也补充进来。特在此mark todo。
